

CTOの原口です。
EC2(g6.xlarge)に Ollama + Open WebUI + qwen2.5-coder-toolsを入れて、ローカルのclineから使ってみたのでその備忘録です。
clineを使った開発者体験は凄まじく、これはこれからの開発は変わる!と感じたのですが、いかんせん僕の使っているOpenAI APIだと値段が高いし、いろいろいじり倒すことに躊躇していました。
なのでまずは簡単にローカルPC(MacBookPro M3pro)にLLMを入れて動かしてみたのですが当然まともに動かず・・・nVidiaを積んだEC2を使ったらどうなるのかな?ということでやってみました。
※ 現状弊社プロジェクトではclineやオープンソースモデルを使った開発は行なっておりません。
本記事は技術検証としてsandbox環境及びサンプルコードで検証したものとなります。
環境
EC2 : g6.xlarge
AMI : Deep Learning Base OSS Nvidia Driver GPU AMI (Amazon Linux 2023)
EBS : 75GB
ロール : SSMセッションマネージャーが使えるロールをつける
PublicIP : 有効化
パブリックサブネットで動かして、セキュリティグループで固定IPのみ許可にしておきました。
構築
SSMで接続して構築します
1sudo dnf update
2sudo systemctl start docker
3sudo systemctl enable dockerollamaをdockerで起動
1docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollamaopen webuiをdockerで起動
1docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --env WEBUI_AUTH=False --restart always ghcr.io/open-webui/open-webui:main設定 & モデルダウンロード
無事に起動してると http://IPアドレス:3000 で接続したら以下の画面になります
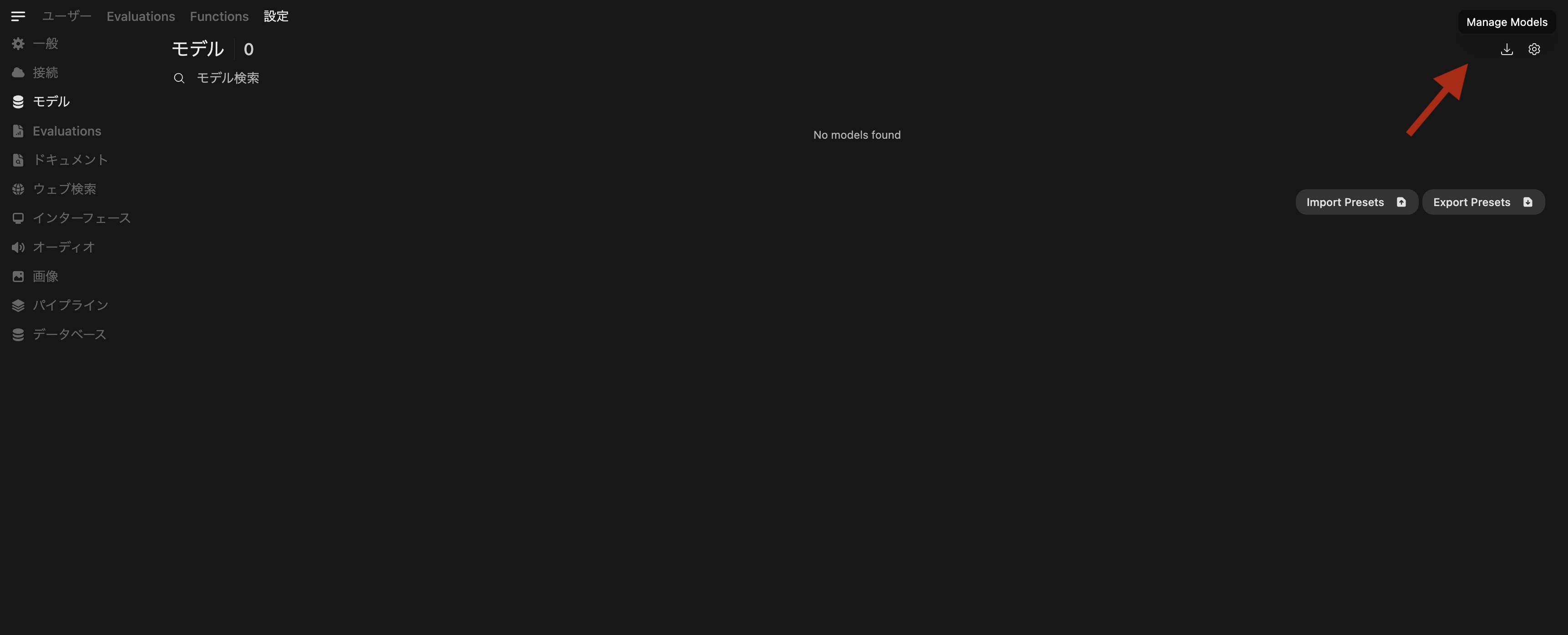
右上のユーザーアイコン → 設定 → モデル と進んで、ダウンロードマークをポチります。
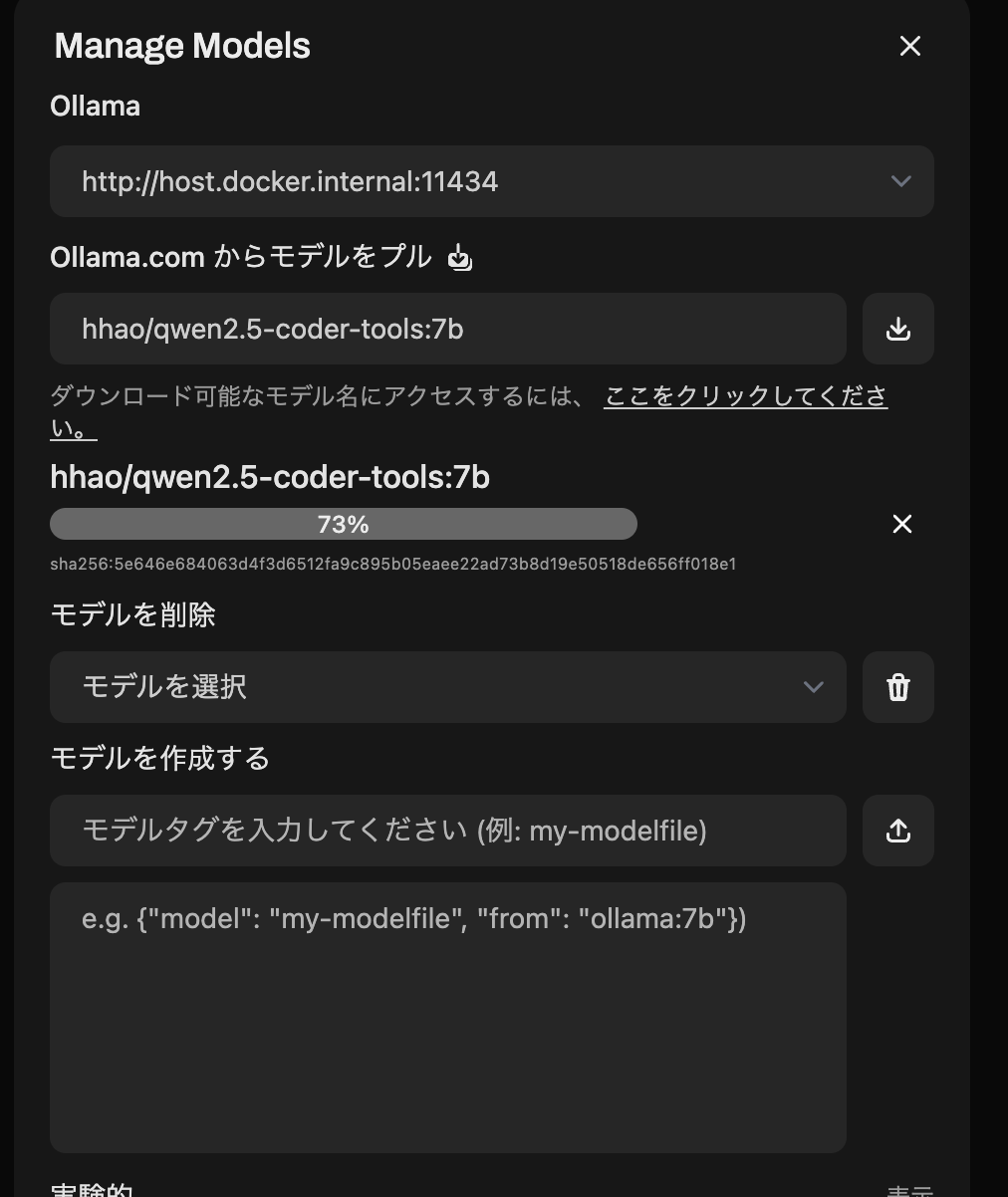
モデルをダウンロード。今回は自分のPCではまともに動かなかった hhao/qwen2.5-coder-tools:7b を入力してプル
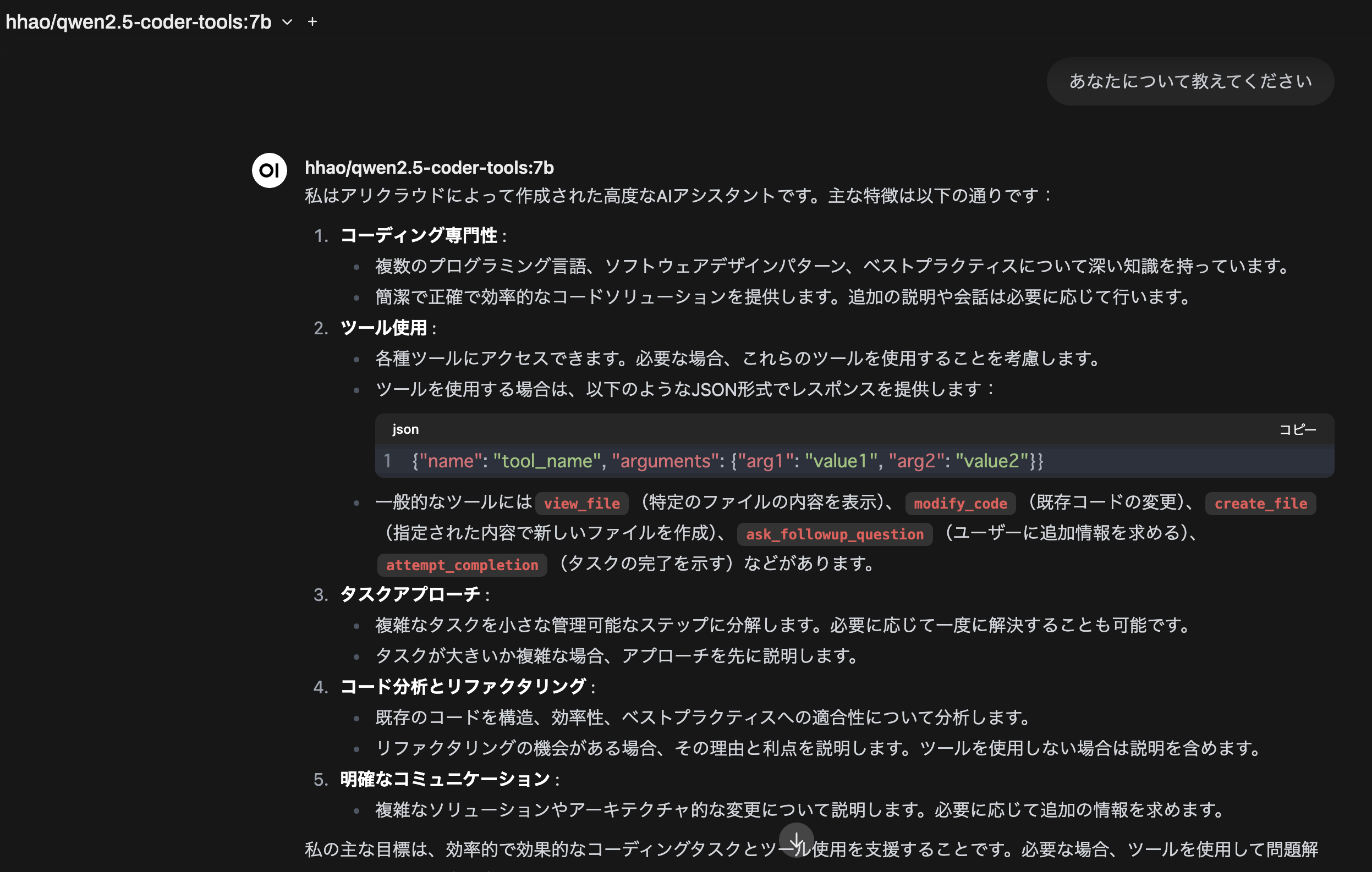
プルが完了したら簡単に動作確認でチャットしてみます。おおーかなり早い
これでサーバー側の設定は完了
clineでLLMサーバーのOllamaを使う
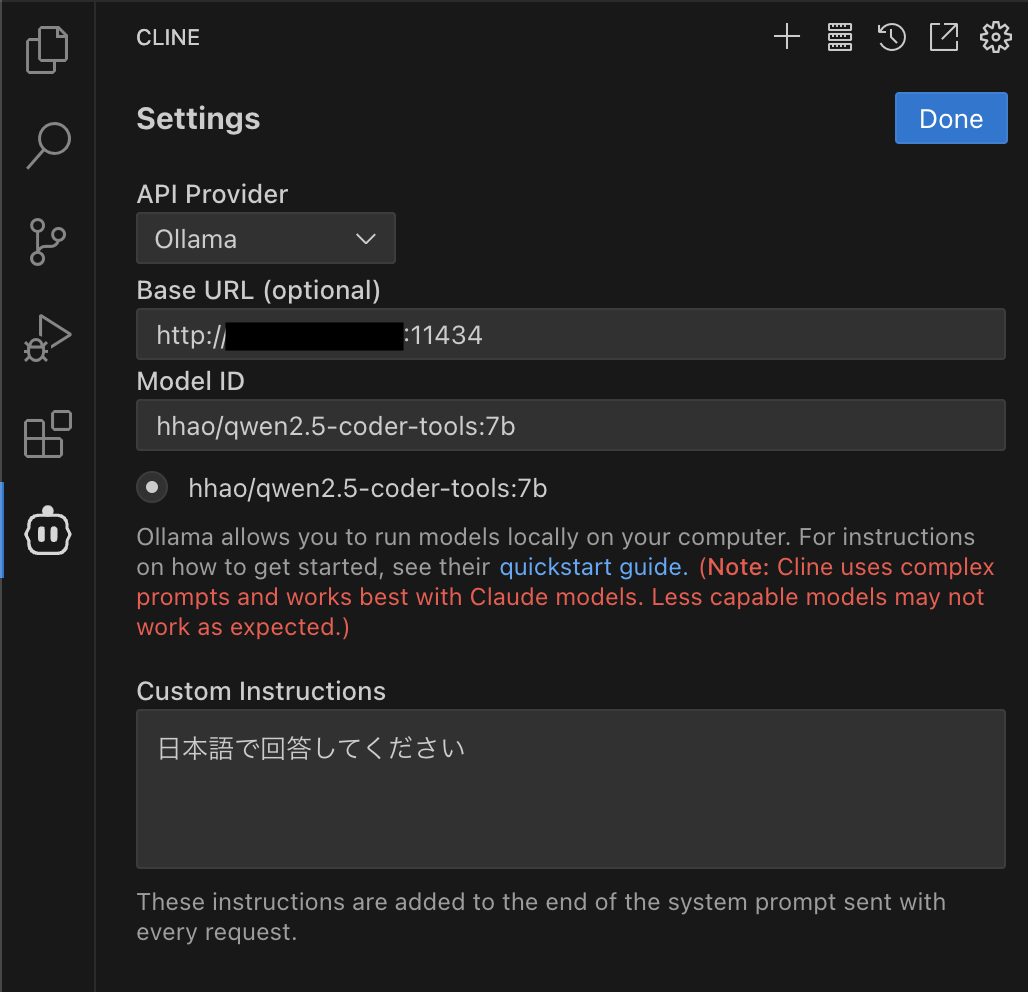
VSCodeのclineの設定にて以下のように設定します。
API Provider : Ollama
Base URL : http://IPアドレス:11434
Model ID : hhao/qwen2.5-coder-tools:7b を選択
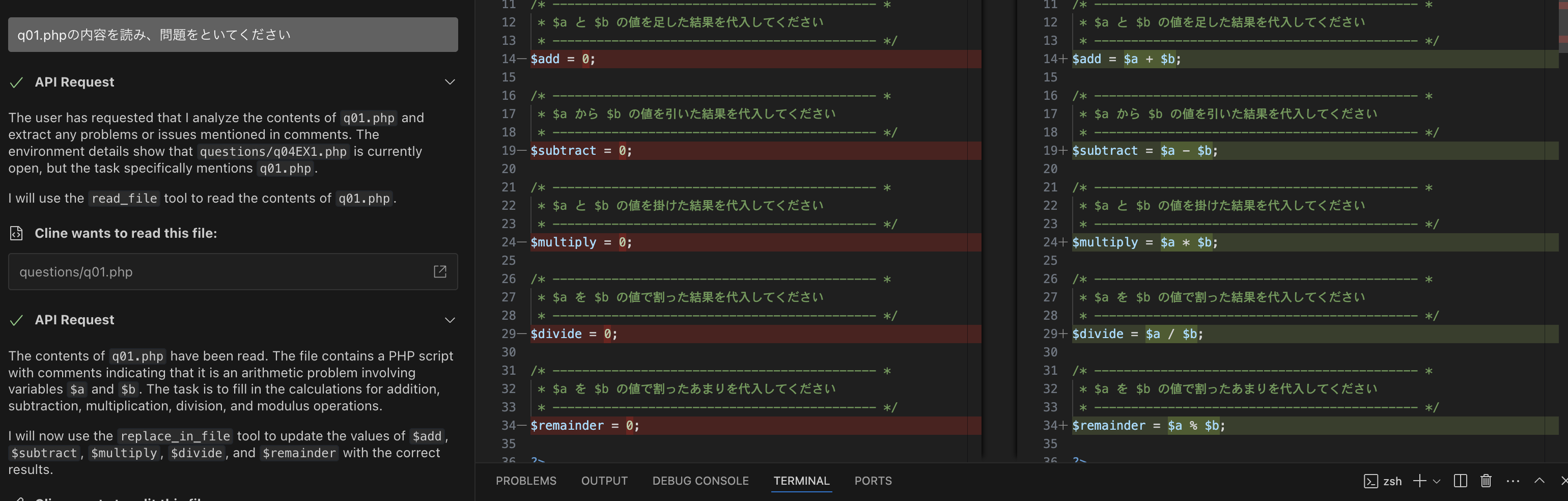
httpだから暗号化されてないですがサンプルプログラムなのでよしとして動かしてみました。
ちゃんと動きました。(日本語にはなってくれなかったw)
所感
実際にバリバリと動かすとかなりおバカな動きになってしまったので、そのあたり、EC2スペックとモデルを変えていろいろ調整していきたいです。
nVidiaのグラボを用意するのはかなり大変ですし、そのあたり簡単に使えてサクッと試せるのはとってもいいです。各種LLMのAPI料金を気にしたく無い時や、特別なモデルをサクッと触ってみたい時、ローカルLLM PCの購入前のテストなど。とりあえずそれなりに動かすという用途だとEC2でLLMサーバーを作ってみるのは一つのいい選択肢かもしれないです。
ちなみに g6.xlarge の料金は USD 1.1672/h でした。